Businesses collect and store more data than ever. This increased volume of data makes serverless analytics applications more appealing. Serverless analytics platforms are scalable, cheaper, and allow great flexibility for ingesting new datasets.
What is data analytics?
Data analytics helps companies increase efficiency and improve performance by letting them discover patterns in data. It answers both strategic and tactical business questions by collecting, transforming, and analyzing data generated by business systems applications. Understanding how data moves through various data sources is a prerequisite for building a data analytics pipeline and transforming collected data into meaningful insights for users.
In a traditional data analytics platform, all necessary components, including data ingestion, storage, and visualization, require the right infrastructure—database, application, and web servers—in addition to software licensing for extract, transform, and load (ETL), business intelligence, and other tools. Onboarding new data or building new analytics pipelines in a traditional analytics architecture can be complex and time-consuming. It requires coordination across business and IT, new ETL workflows, additional infrastructure, and—most importantly—time and resources.
With ever-increasing volumes of data, this process of negotiating, allocating resources, and provisioning extra capacity has become inefficient. Businesses are demanding easier ways to integrate new data sets on a continuous basis in a more self-service, agile, timely, and cost-efficient manner.
Why build a serverless data platform?
Serverless data analytics provides many benefits and the agility required of a modern data platform solution. First, there is no requirement for heavy upfront infrastructure investment. It is a completely on-demand execution model and companies only pay for the resources consumed. Second, it can be simpler and quicker to provision services. Third, serverless apps are scalable—you can start small with little investment and gradually increase (or decrease) capacity. Finally, serverless data platforms are “decoupled,” which means the architecture allows different tasks to be performed in separation and isolation. This means that if a microservice fails to execute a single task it doesn’t affect the full operation.
What is serverless data analytics?
The architecture of a serverless data platform is not much different foundationally than a traditional architecture; however, the tools are different. The diagram below shows the architecture of a data lake-centric serverless data platform. Let’s look at some of the AWS services within each that can be used to build a serverless data platform.
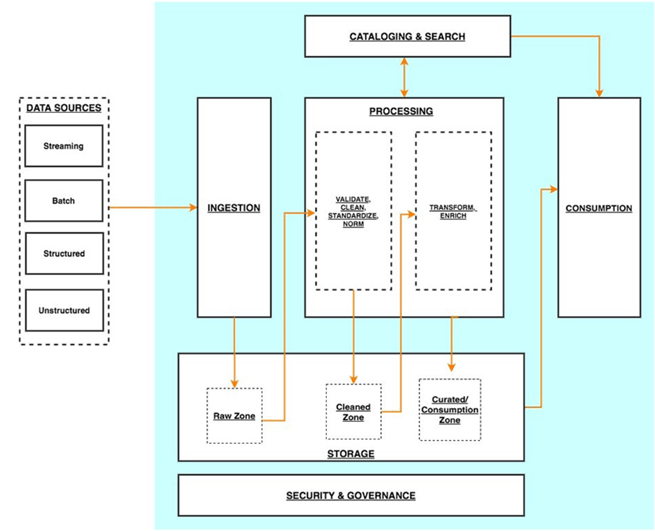
Data ingestion
AWS Data Migration Services (AWS DMS) can connect to various data sources (both RDBMS and NoSQL) and ingest data into a central data lake. It is best suited for connecting to operational database sources. It’s important to note that for many sources DMS can perform an initial load of data and then switch to ongoing replication, which means that it will capture only Change Data Capture (CDC) data going forward.
Amazon Kinesis makes it easy to collect, process, and analyze real-time streaming data. API Gateway provides the ability to create and maintain APIs and integrate with other AWS services. For example, used in conjunction with Kinesis and Lambda, API Gateway can be leveraged to ingest data from web apps, mobile devices, etc.
Data storage
S3 is an object storage service. It provides the foundation for the data lake—the central location where all raw structured and unstructured data is collected. Data is then organized in buckets and can flow from one bucket to another (raw, cleansed, consumption zone) as it gets transformed. S3 is a durable, highly available, and cost-effective service that can store very large volumes of data.
Processing
AWS Glue is a fully managed ETL service allowing you to transform and load data from S3 without the need to deploy or manage clusters. This is a robust offering that includes Glue jobs, crawlers, workflows, ML transformations, and a data catalog, to name a few.
AWS Lambda allows you to run functions and basic tasks without provisioning or managing any servers. Lambda functions can be written in Python, Java, Javascript, etc. Lambda can be used to transform raw data into desired formats.
Data cataloging
Lake formation allows you to set up and secure a data lake built on S3. Then, the cataloging of data assets in the lake can be handled using AWS Glue.
Consumption layer
Athena is a serverless data querying tool that makes it easy to analyze data in S3 without the need to store the data into a database first.
Amazon Redshift Spectrum is a fully managed data warehouse service that does require provisioning of compute nodes. However, a feature called Spectrum can be leveraged to run queries on structured and semi-structured datasets in S3, without the need to first load the data into the Redshift cluster.
Amazon QuickSight provides AWS native business intelligence tools allowing you to create interactive dashboards. QuickSight can natively connect to your data sitting on S3 using the Athena connector. In this instance, the S3 data could be catalogued through AWS Glue and accessed by QuickSight via Athena. This eliminates the need to have an RDS database as the source for the visualization, as well.
Amazon SageMaker provides fully managed services that allow you to interact with the cleansed data to build, train, and deploy ML and predictive analytics models.
Using a completely serverless architecture can benefit your organization in a number of ways. It’s a cheaper option compared to traditional data analytic. It also provides a simpler and more flexible way to ingest new data sets. And importantly, it is scalable. Using serverless technology allows you to start small and scale the solution only when needed. Last but not least, it is convenient for ad-hoc querying without the need of heavy ETL.
Infinitive has vast experience in Data Analytics, particularly building serverless platform. Infinitive can help customers build modern and flexible data solutions while ensuring optimal cost and security. With a proven Enterprise Data Management framework, we have helped clients in Financial Services, Education, Media, and other sectors to take harness the power and ultimately convert data insight into additional revenue.