Summary
Infinitive was retained by Morehouse College to help drive its use of internal data to improve student retention and persistence.
Morehouse is the only historically Black, all-male, four-year liberal arts institution in the United States, with a history dating back over 157 years.
Through a Strategic Data Planning workshop, we worked with the Morehouse leadership team to identify strategic objectives important to the college and the foundational data infrastructure needed to support those objectives. Focusing narrowly on the most important of these objectives, student retention and persistence, Infinitive created a roadmap for implementing a modern cloud-based data architecture with advanced analytics and machine learning (ML)to serve the use case.
With the strategic goal in mind, a discovery process was initiated to identify Morehouse College’s data to enhance student persistence. The data architecture we designed included a Data Lakehouse built on AWS (Amazon Web Services), ingesting persistence-related data from Morehouse systems like Banner and Starfish. While working with the stakeholders, a list of metrics relevant to persistence was identified to be tracked through a QuickSight dashboard. Besides the dashboard, Infinitive data scientists implemented a predictive machine learning model to identify students at risk of not persisting. This blog focuses on the machine learning effort while giving a quick overview of the entire data architecture.
Enhancing Student Persistence through Data Analytics at Morehouse
Student Retention and Persistence
At its most basic level, student retention and persistence are about keeping the student in school and progressing toward graduation. The stated mission of Morehouse is to develop men with disciplined minds who will lead lives of leadership and service. To achieve this mission, it is vital to graduate every Morehouse man. Several metrics, such as retention rate (% of students retained) and 4-year graduation rates, can be used to track success in this endeavor. While these metrics are descriptive (they describe how well the college is doing in terms of student success), there is also an opportunity for predictive (e.g., forecast the probability of any particular student persisting) and prescriptive (e.g., identify specific interventions for students at risk of not persisting) analytics. This is the realm of machine learning, where models can train on historical data to identify patterns that predict student success and project those patterns on profiles of current students.
Laying the Data Foundation
A key enabler for advanced analytics is a flexible data architecture. This architecture should be capable of supporting a variety of data sources, ingestion, transformation patterns, traditional business intelligence (BI), and ML – all in an extensible, scalable form.
Infinitive designed a cloud-based architecture for Morehouse, with a Data Lakehouse built using serverless AWS services like S3, Glue and Redshift – with analytics capabilities utilizing Quicksight and Sagemaker. This lays a low-cost foundation that will grow with Morehouse’s needs. We also implemented data pipelines to draw data from key sources like Banner (Student Information System and ERP) and Starfish (Student Success Platform) and create an integrated view of the students within the Lakehouse.
We then built a framework for adding data quality checks and transformations in this pipeline to enhance the quality and usability of the data. In addition, we developed a dashboard where stakeholders can track key metrics for student success.
Data Preparation and Feature Engineering
The first step in developing a predictive model for student persistence is to develop a hypothesis on the factors that affect student success. Infinitive’s data science team conducted a series of interviews with key personnel responsible for student success at Morehouse, from admission to engaged alumnus, to gain insights from decades of experience addressing this topic at the college. As an outcome of this phase, we created a list of candidate features, which could be broadly bucketed into three categories: academic, financial, and social. Next, we worked with the IT team at Morehouse to identify where to find data relevant to these features in the source systems and created data pipelines and a feature table in the Data Lakehouse, which is refreshed periodically.
As an initial step of data preparation, we explored the data’s characteristics, like the distributions of numerical features and class balances of categorical features. We identified low-fidelity variables to prune from our feature set and noted any imbalances that could influence our sampling method or choice of algorithm.
We also used various imputation methods to deal with missing data for some features. From the initial set of features, we engineered additional ones (e.g., temporal variables like total time in school, time between semesters, and custom variables to denote the enrollment and graduation status of students) and applied this designation to each semester tied to their IDs. We combined these temporal variables and graduation status to create our target variable, graduated_in_4_years. We subsequently dropped any graduation status, identified information from the training set and labeled our categorical variables.
Model Development
Before building a model in SageMaker, Infinitive selected an appropriate sample to pull our training data. To do this, we excluded current Morehouse students who had enrolled for less than four years and any student who had left Morehouse for one or more years between semesters. The remaining sample contained only graduates, students who had been at Morehouse for 4+ years, and students who had not completed their degrees (all with at most one year between semesters).
We used a stratified sampling method to separate the data into a training set to build base-level models, a validation set to tune hyperparameters and select the best-performing model, and a testing set to evaluate the final model’s performance. Initially, we used logistic regression for variable selection, choosing inputs based on feature importance weights, which reduced our feature list from over 100 features to 22.
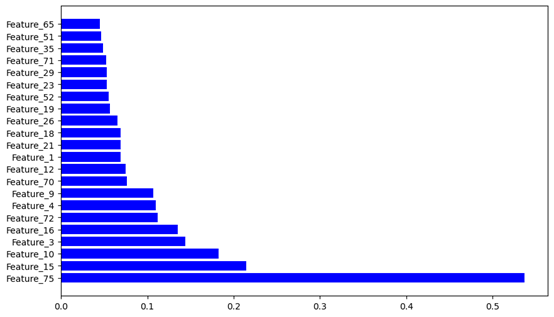
Using these selected features, we built a logistic regression model, decision tree, random forest, and gradient boosting classifier on top of our training data. All four models performed similarly well, so we proceeded with the decision tree classifier, which offered the best balance of performance, cost, and explainability. We then constructed a parameter grid to tune this model and applied 5-fold cross-validation to select the optimal hyperparameters for our final model.
Model Deployment
Infinitive’s ML workflow lived entirely inside of Jupyter notebooks within our Amazon SageMaker Studio Lab, which fit nicely into our existing architecture:
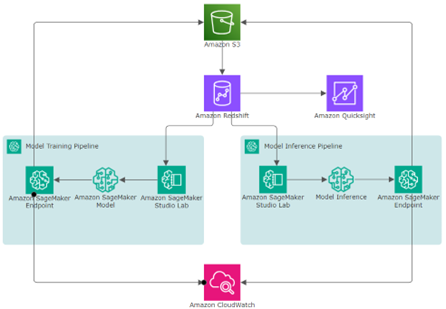
We used Redshift to create external tables on top of our S3 buckets and operated in SageMaker to train, test, and deploy our model. We set our model training and model inference pipelines on two different schedules. The training pipeline runs prior to each new semester to re-train the model on new data and the inference pipeline performs batch inference weekly. The results are made available as numeric risk scores and binary risk classifications on a QuickSight dashboard for Morehouse personnel who can then curate the list of at-risk students and create customized intervention plans for them.
Next Steps
Long-term model performance and predictive adaptability will involve a multi-faceted approach. Built-in feature importance analysis can help identify influential features and provide insight into why certain predictions were made.
To monitor model performance, Amazon CloudWatch alarms can be configured to alert engineers of deviations from expected performance metrics. Automated pipelines that re-train the model within SageMaker using new data every semester can iteratively improve the model and address issues identified over time via feature importance and monitoring analysis.
Conclusion
Infinitive worked with Morehouse College to identify a strategic goal, student persistence, and defined a data architecture that fits Morehouse’s needs. This architecture included a Data Lakehouse, the data engineering components to feed the Lake, and the analytics components to perform traditional BI (dashboards and reports) and advanced analytics (ML models). The architecture was designed to use serverless offerings from AWS to minimize administrative costs, and to scale up and down as needed to minimize costs. Infinitive populated the Lakehouse with data relevant to student persistence and developed a dashboard to visualize key metrics related to this goal. Further, we developed an ML model to provide a predictive and prescriptive view for current students at risk of persisting.
For modern data-driven organizations, it is imperative to expand their analytics capabilities to embrace AI/ML. Traditional descriptive analytics like dashboards and reports, as well as people’s experience and intuition, can now be augmented by ML models. These models can churn through historical data and learn patterns (e.g., how various factors have affected student persistence outcomes in the past) and use that learning to predict outcomes for current and future students. Armed with these predictions and explanations of factors influencing the risk for each student, higher education institutions will be able to intervene when necessary and improve outcomes more effectively. This holds the promise of a more effective, efficient, and productive student success program and a cascade of benefits that result from helping students succeed.
To discuss our work at Morehouse College or Infinitive’s data and AI capabilities overall, e-mail don.rippert@infinitive.com or call us at +1 (703) 554-5500.